在機器學習中,欠缺擬和 ( Underfitting ) 與過度擬和 ( Overfitting ) 是兩個主要評估模型性能的標準,所謂的「擬和」,就是指讓模型的預測值能夠接近實際值的過程,訓練模型的目的主要是為了讓模型在面對到陌生的輸入資料時,能夠輸出可靠的預測表現,也就是提高模型的泛化能力 ( Generalization ),欠缺擬和與過度擬和就是拿來衡量模型是否具有良好泛化能力的標準。
所謂欠缺擬和就是指模型輸出的預測值還沒有辦法準確落在實際值上面,也就是還沒掌握到資料潛在的模式或趨勢,因此模型的預測能力較差,其預測值和實際值的偏差 ( Bias ) 較大,欠缺擬和的模型對資料中的細節或噪音 ( Noise ) 也較不敏感,無法完整的學習資料並去擬和每個資料點,更無法反映資料的複雜性,像是下圖中的紅線 ( 預測值 ) 無法包含大部分的綠點 ( 實際值 ) 就是遇到欠缺擬和的問題,下圖中的綠點皆為訓練資料,前面提到欠缺擬和就是模型經過訓練後,結果跟實際差很多,這就像是你要考試,考試的題目你都看過了,你為了要高分就直接把答案記下來,照理說這樣你考出來的表現應該要很好,但是你背東西沒有方法導致你一下就忘,這就表示你模型對訓練資料 ( 考題 ) 的擬和能力 ( 答對能力 ) 較低,這就是模型欠缺擬和的情況。
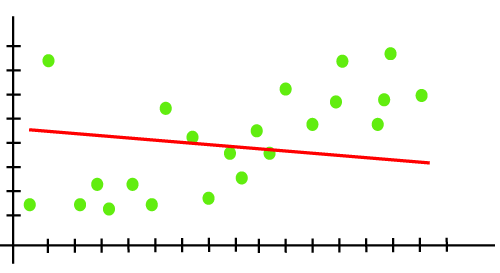
面對到這種無法擬和實際值的情況,透過下面方法能夠解決模型缺乏擬和的問題,以增加模型的擬和能力:
欠缺擬和問題的模型經過改善後,就像是你記題目變得有方法,能夠記下夠多的題目也記得越熟,這就讓你在考試的表現變好,代表模型在擬和訓練資料的表現越好。
上面提到對於要解決模型欠缺擬和的問題,會不斷地用一些手段去改善,目的就是為了去擬和訓練資料,然而因為模型在訓練時盡力地去擬和訓練資料,模型就會對訓練資料的細節較敏感,當訓練資料中有存在噪音、偏誤或某中既定資料模式趨勢時,模型會把這些全都擬和進去,模型或許能夠極度擬和訓練資料,但也僅限於對訓練資料而以,換在其他陌生資料 ( 測試資料 ) 上可能會受先前在訓練資料中的噪音影響而降低表現,表示模型的泛化能力 ( Generalization ) 極低。
我們通常會把訓練資料和測試資料分開,訓練資料用來訓練模型,測試資料用來測試模型最終效能,當模型訓練完後使用訓練資料去測試模型的效能時,因為模型在訓練時都已經看過這些資料而且擬和,所以預測、擬和表現通常較佳,過度擬和就像是你考試把考題 ( 訓練資料 ) 都先死記硬背下來 ,在考試時因為這些題目你都看過了,所以表現當然較佳,也就在訓練資料上模型擬和表現較佳,但換成在測試資料,對模型來說是陌生未看過的,對於沒看過的考題,僅靠先前死記硬背就沒用了,模型的表現就會不佳,這種模型在訓練集上表現佳而在測試集表現欠佳的情況稱為過度擬和。
對於模型過度擬和的問題可以用下列方法解決:
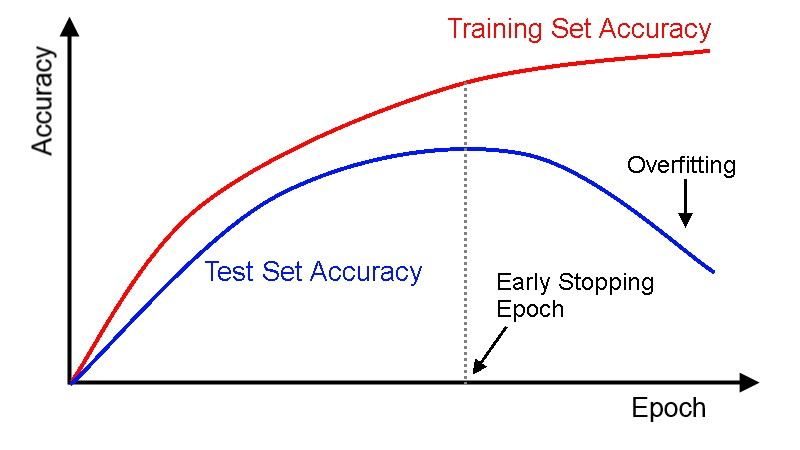
在生活考試中,通常會建議不要用死記硬背的方式刷題,要刷得活一點,從每題中了解到解題竅門或題型模式,在面對到沒看過的考題才能夠活用,而我們訓練模型的目的也是如此,就是為了不要發生過度擬和的情況,模型過度擬和就是過度的依賴且掌握先前那些看過的資料而變得死板,希望模型能夠在訓練資料中掌握特徵資料與標籤資料之間的關係,面對到陌生資料時就能夠活一點,較活的模型泛化能力也較高,至於用死板的方式 ( 死記硬背刷題 ) 反而會降低模型的效能。
今天我們了解到欠缺擬和與過度擬和之間的差異,以及改善這些問題的方法,對於模型的誤差損失,明天我們就要介紹兩個指標 - 偏差 ( Bias ) 與方差 ( Variance ),那我們下篇文章見 ~
https://www.javatpoint.com/overfitting-and-underfitting-in-machine-learning
https://cynthiachuang.github.io/EarlyStopping-Callback/

